|
Wancong (Kevin) Zhang I am a second year PhD student at NYU Courant, specializing in deep learning under the guidance of Yann LeCun. Prior to my PhD, I worked as a senior researcher at AssemblyAI, where I led the developments of Conformer-1, Conformer-2, and realtime automatic speech recognition (ASR) models. I earned my M.S. degree from NYU Courant Institute's Computer Science Department, where I had the privilege to collaborate with Nicolas Carion, Marzyeh Ghassemi, and Rajesh Ranganath. Before starting my AI journey, I explored the world of stem cell and molecular biology research at Harvard Stem Cell Institute. Email / CV / Google Scholar / Github |

|
News
|
Research (Updated 09/2025)I believe the ability to learn from observations and interacting with the world in an unsupervised manner is a crucial stepping stone to unlocking general intelligence. My primary research focus revolves around self supervised learning (SSL) and novelty guided explorations, with an emphasis on their applications in computer vision and control. |
|
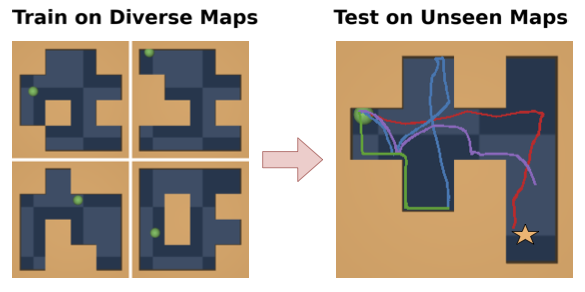
Learning from Reward-Free Offline Data: A Case for Planning with Latent Dynamics Models
Wancong Zhang*, Vlad Sobal*, Kynghyun Cho, Randall Balestriero, Tim Rudner, Yann LeCun Website Advances in Neural Information Processing Systems (NeurIPS), 2025 Best Paper Award, ICML 2025 Workshop on Building Physically Plausible World Models This work introduces zero-shot planning using the Joint Embedding Prediction Architecture (JEPA) trained from offline trajectories, demonstrating its strengths in generalization, trajectory stitching, and data efficiency compared to traditional offline RL. |
|
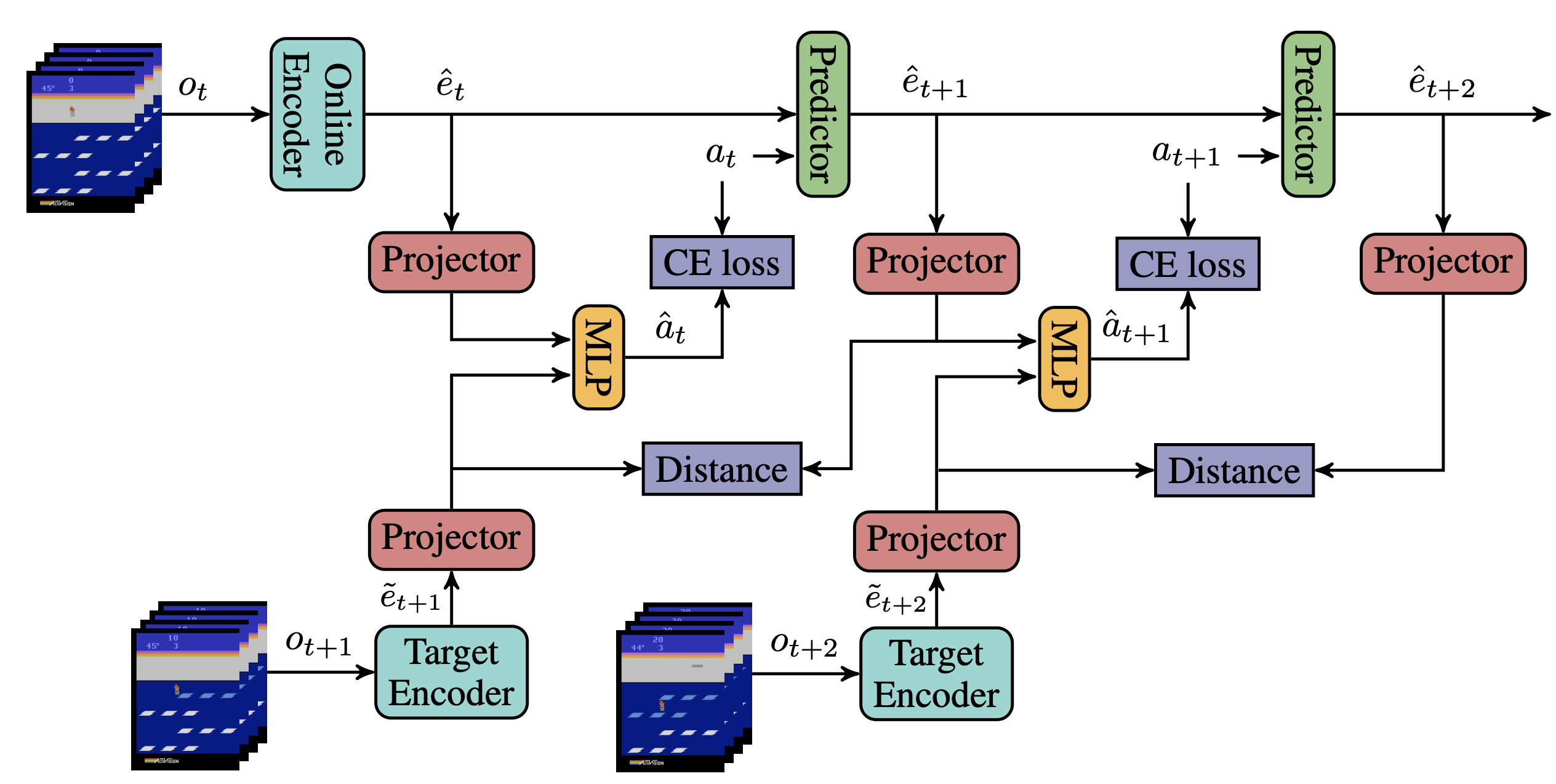
Light-weight probing of unsupervised representations for Reinforcement Learning
Wancong Zhang, Anthony GX-Chen, Vlad Sobal, Yann LeCun, Nicolas Carion Code Reinforcement Learning Conference (RLC), 2024 Presents an efficient probing benchmark to evaluate the fitness of unsupervised visual representations for reinforcement learning (RL). Applied it to systematically improve pre-existing SSL recipes for RL. |

|
Conformer-1: Robust ASR via Large-Scale Semisupervised Bootstrapping
Wancong Zhang, Luka Chkhetiani, Francis McCann Ramirez, Yash Khare, Andrea Vanzo, Michael Liang, Sergio Ramirez Martin, Gabriel Oexle, Ruben Rousbib, Taufiquzzaman Peyash, Michael Nguyen, Dillon Pulliam, Domenic Donato 2024 Showcases an industrial-scale end-to-end Automatic Speech Recognition model trained on 570k hours of speech audio data using Noisy Student. It achieves competitive word error rates against larger and more computationally expensive models. |
|
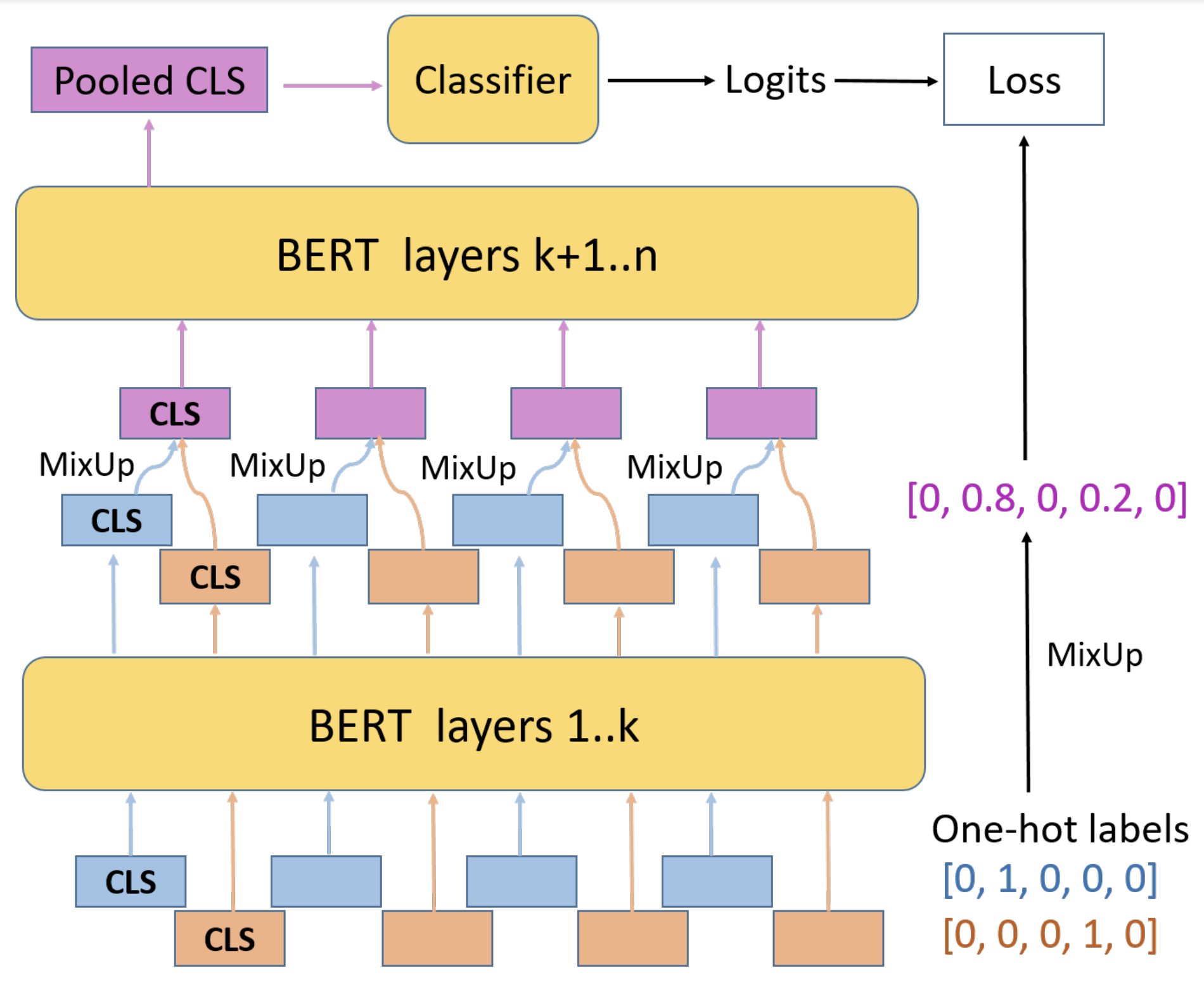
MixUp Training Leads to Reduced Overfitting and Improved Calibration for the Transformer Architecture
Wancong Zhang, Ieshan Vaidya 2021 Adapts the computer vision data augmentation technique MixUp to the natural language domain, reducing calibration error of transformers for sentence classification by up to 50%. |
|
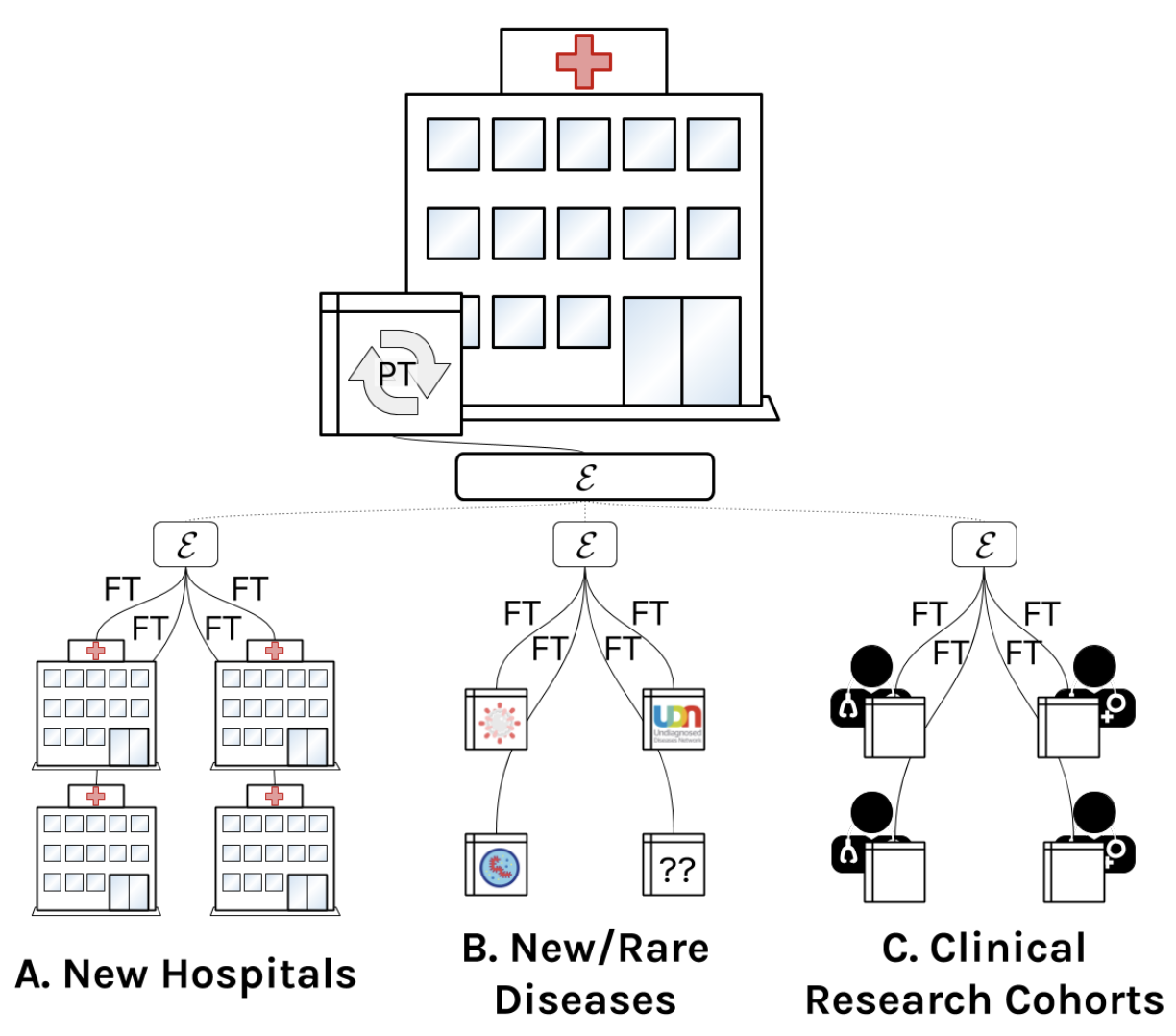
A comprehensive EHR timeseries pre-training benchmark
Matthew McDermott, Bret Nestor, Evan Kim, Wancong Zhang, Anna Goldenberg, Peter Szolovitz, Marzyeh Ghassemi Conference on Health, Inference, and Learning (CHIL), 2021 Establishes a pre-training benchmark protocol for electronic health record (EHR) data. |
Teaching |

|
Deep Learning (DS-GA 1008), Fall 2024
|